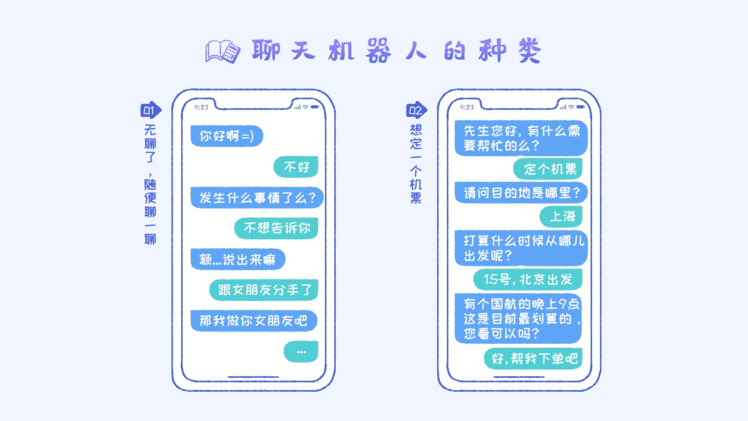
聊天机器人的分类
对于聊天机器人,通常有两种类型:一种是闲聊型的,另外一种是任务导向型的。从上述图中可以看出,第一个聊天机器人显然没有什么任何目的性,不是为了完成某一个任务而设计的。相反,第二个聊
天机器人是为了完成某特定的任务而设计的。在本章我们主要还是来讨论第二种类型的机器人。比如机票预定机器人、订餐机器人、心理咨询机器人、法律机器人等等。至于方法论层面,本章我们主要
来讨论基于意图识别的方法。 当然,除了这个还可以通过检索式、生成式的方式来搭建。下面我来给大家讲一下基于意图识别式方法论的思想是什么。
以智能音箱为例来解释整个流程当中都涉及到哪些模块。
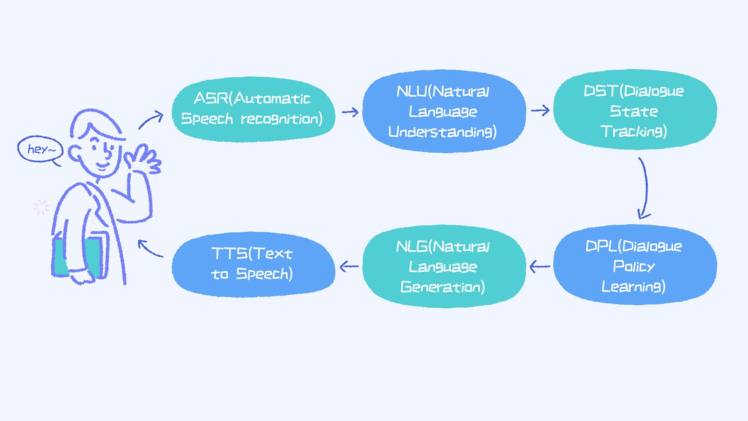
这是一个很经典的流程。下面我们一一来看一下。第一,首先是ASR的部分。 这部分的功能其实就是语音识别,比如把人的语音转换成文本。ASR部分依赖语音识别技术。在国内,科大讯飞算是最成功的语音识别技术提供商,所以一般情况下可以直接调用他们的接口来实现ASR模块也是可以的。另外,ASR的模块通用性比较强,所以很多应用不太建议自己去开发一个ASR, 而是使用一个现成的API服务。
第二、NLU部分。
这部分的功能其实就意图识别和实体识别,比如用户说了一句话:“我想定机票,从北京出发到上海的”。那对于这句话,我们通过NLU模块就可以识别出来这个意图是“订机票”,同时,也提取出两个实体“北京”和“上海”。当然,对于订机票的意图来讲,我们只知道出发地和目的地是不够的。另外,我们也需要知道时间。如果这三个信息都具备,后台系统即可以通过数据库查询来获得满足条件的机票信息,进而让用户选择最合适的。
所以,你可以认为这种系统的核心无非就是需要从用户那里不断地获取相应的实体信息,如果获取完毕就可以调用后台数据库。相反,如果有些信息还没有获取到,那就直接跟客户去问,比如“你想什么时候出发呢?”对于聊天机器人来讲,NLU部分至关重要,因为后续所有的工作依赖于NLU的结果。对于NLU我们会在下一节里给大家做更详细的介绍。
第三、DST部分。这部分其实就是来存储对话的状态。这个状态无非就是来保存信息的完整性。比如目前的意图是订机票,那就需要来跟踪针对于这个意图的实体信息。
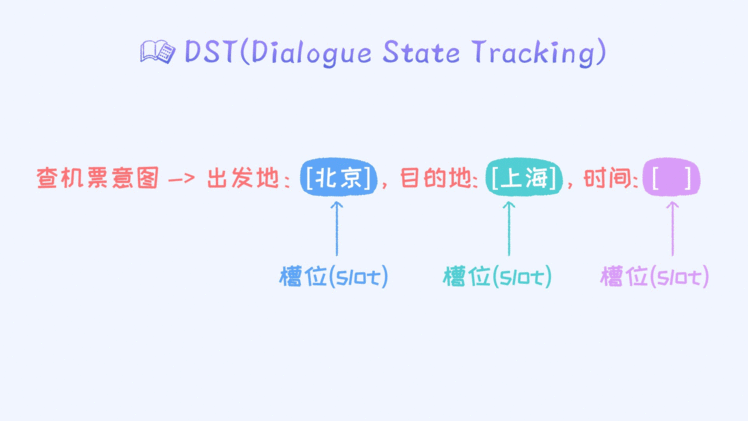
上图表示的就是一种状态。对于一个意图其实有多个槽位,然后每个槽位一开始是空的。随着对话的进行,槽位信息被不断地填充。最终会触发数据库调用。槽位信息的获取其实就是依赖于意图识别模
块。
第四、DPL部分。这部分是用来维护目前对话状态和需要做的动作。举个例子,比如目前的对话状态是查机票,但缺少时间的信息。那这时候,机器要做的是询问用户时间信息。这里有个问题是:如果一
开始有三个槽位,分别是时间,目的地和出发地,而且都是空的。那接下来第一个要询问的是哪方面信息呢?其实没有一个固定的答案! 这就要看我们想如何设计。 也就是处于某一种状态下,接下来要问
什么,可以完全依赖于我们提前预定号的设计逻辑来实现。这部分我们通常使用有限状态机来实现(finite state machine),具体什么叫FSM不用太在意,看完下面的这幅图应该就明白了。

从图里面可以看到,针对于每一种状态我们其实定义好了一个明确的行为(action),可以理解为接下来需要做的事情。那这些谁来定义呢? 当然要根据业务场景来决定的。把上述这些条件写在一起的话,
就能得到一个有向图:每个节点是状态,每一条边是需要做的action。
第五、NLG部分。这部分就是生成一个文本,最简单的方式是直接通过手动的方式来定义指定的文本。举个例子,如果接下来要做的action是Ask_Location, 那就直接返回:“您想在哪里开会呢?“。

所以,都可以提前定义好的。但这种方法也有一些问题比如回复的内容每次都是一样,导致用户觉得很枯燥。所以,让回复具备多样性也是一个比较重要的问题。如何让每次的回复有些不一样呢? 一种解
决方案是提前定义好多种不同的回复,然后从里面选一个来返回。还有就是回复的时候可以动态地去生成一些,但这肯定是有挑战的。
还有就是回复的时候可以动态地去生成一些,但这肯定是有挑战的。一个经典的例子是AI主播,用一个名人的音色来把提前设计好的文本读出来。当然在AI主播里,我们还需要模仿嘴型等视觉效果,所以
难度更大。TTS部分跟语音领域紧密相关,所以在这里不再阐述。如果你想做一款类似AI主播的系统,那还需要跟计算机图形学相关的技术,比如Computational Geometry。
意图识别是分类问题
我们做任何事情其实都带着意图的,而且做某一类事情的时候可以有不同的意图。举个例子,到了南航的官网,一个人可能有查机票、退机票、订座位等不同意图。所以意图识别本质上来讲就是多分类问题。输入为文字,输出为某个特定的意图。这就类似于情感分析,只不过情感分析是二分类问题,但这里的意图识别是多分类问题。

文本处理和分类
对于文本分类问题来讲,核心是文本处理。上面图里列了几个常用的文本处理技术。其实我们在之前的课程里都讲过这部分的内容。在本章的案例作业里也需要用到。等我们把文本转换成特征向量之后,就可以通过分类模型来训练了。分类模型有SVM,神经网络等等。具体选择什么模型就要看效果了。一般情况下,我们都会尝试多个然后选择其中最好的。或者,把不同种类的模型最后混合在一起使用,成为一个集成模型。
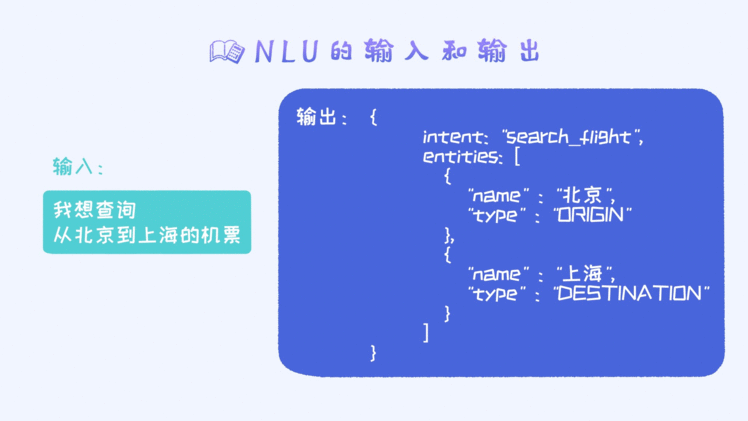
所以从这里可以看到,输出一般分为两个部分,一个是意图,另外一个是从句子里抽取出来的实体。并且,每个实体有对应的类型。对于实体识别的任务,我们称之为"sequential labeling problem",一般使用序列模型来解决。在文本领域,常用的序列模型有CRF相关的系列模型,比如LSTM-CRF, BERT-BILSTM-CRF等等。具体细节暂时不做过多介绍了。
提供一个项目,需要根据训练数据来搭建意图识别模块
完成意图识别任务。 给定一段文字,然后识别出文字所表达的意图, 如上所述。

在这个项目里,你们需要做几件事情:
做必要的文本预处理,比如分词,清洗、低频词过滤等工作。
![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有